In this long, and now a little old, page you can find a comparison among the old version of BFQ (prior to v1), SCAN-EDF, YFQ, CFQ, C-LOOK and Anticipatory. You can also find all the stuff related to the first implementations of BFQ, YFQ and SCAN-EDF made by Fabio Checconi and me, and to the performance tests we ran with each of these six schedulers.
- Budget Fair Queueing (BFQ) is a Proportional Share, or equivalently Fair Queueing, disk scheduler that allows each process/thread to be assigned a fraction of the disk bandwidth. BFQ assigns a budget, measured in number of sectors, to each process and serves budgets according to B-WF2Q+, a modified version of WF2Q+.
- Yet another Fair Queueing (YFQ) is a research scheduler based on the same bandwidth allocation scheme as BFQ, but it serves requests, possibly of different processes, in batches.
- SCAN Earliest Deadline First (SCAN-EDF) is a research real-time disk scheduler in which each request is associated with a completion deadline, and the requests with the earliest deadline have the highest priority.
- CFQ and Anticiptory (AS) are two Linux schedulers: the first serves each process for a given time slice in a Round-Robin fashion, whereas, as C-LOOK, the second serves requests in ascending position order.
BFQ, CFQ and AS (may) adopt disk idling to handle deceptive idleness. In addition to the top-level description of how BFQ works, you can find all the details about the algorithm, deceptive idleness and other issues in this technical report (to appear on Transactions on Computers). We could not find any Linux implementation of either YFQ or SCAN-EDF. So, to compare both schedulers against BFQ, we implemented them for 2.6.21. Especially, this is the patch that adds BFQ, SCAN-EDF and YFQ to 2.6.21.
The first BFQ proposal (for 2.6.25) was recorded on kerneltrap.org by Jeremy Andrews, whereas the second one (extended version for 2.6.28-rc4) was reviewed on lwn.net by Goldwyn Rodrigues. See the home of this mini-site for the latest available BFQ patches.
In the rest of this page we report a comparison among BFQ, YFQ,
SCAN-EDF, CFQ, AS and C-LOOK. Then a summary of the results of our
experiments.
A longer description and comparison of the schedulers, together with a
more detailed description of the experiments and of the results can be
found in the above mentioned technical
report. Finally, all the results and the programs used to
generate them can be found in this compressed file.
Comparison among the six schedulers
BFQ has been designed to achieve high throughput and tight guarantees, in terms of both bandwidth distribution and request completion time.
Especially, defined the reserved service of a process over a time interval as the minimum amount of service that, according to its reserved fraction of the disk bandwidth, the process should receive during the time interval, BFQ guarantees to each process an O(1) deviation, over any time interval, with respect to its reserved service. BFQ owes to CFQ the idea of exclusively serving each application for a while.
The time-based allocation of the disk service in CFQ has the advantage of implicitly charging each application for the seek time it incurs. Unfortunately this scheme may suffer from unfairness problems also towards processes making the best possible use of the disk bandwidth. In fact, even if the same time slice is assigned to two processes, they may get a different throughput each, as a function of the positions on the disk of their requests. On the contrary, BFQ provides strong guarantees on bandwidth distribution because the assigned budgets are measured in number of sectors. Moreover, due to its Round Robin policy, CFQ is characterized by an O(N) worst-case jitter in request completion time, where N is the number of processes competing for the disk. On the contrary, thanks to the accurate service distribution of the internal B-WF2Q+ scheduler, BFQ exhibits O(1) delay.
To prevent seeky processes from (over)lowering the throughput, if a process is consuming its budget too slowly, it is deactivated and unconditionally (over)charged with a maximum budget. See the code for details.
Differently from BFQ and CFQ the original SCAN-EDF and YFQ algorithms do not take the deceptive idleness problem into account. However, in our implementations, we added the waiting for the arrival of the next requests for at most Tw seconds before serving the next request or batch of requests.
Despite this extension, YFQ still achieves a low throughput and fails to guarantee the desired bandwidth distribution in presence of synchronous requests (see the section on the experimental results). When asked for the next requests to serve, YFQ dispatches an entire batch, which in general contains requests issued by different processes. First, this reduces the possibility of near or sequential accesses of the same processes. Second, if an application has a (much) higher weight than the others but it issues synchronous requests, then no more than one request of the application will be however served for each batch.
Another problem shared by YFQ, SCAN-EDF and all the timestamp-based scheduler we are aware of, and dealt with in BFQ through some special timestamping rules, is that if a scheduler delays the completion of a request, it actually delays the arrival of the next synchronous request of the same process. If these delayed requests are not treated in some special way, the process looks like asking for less bandwidth than expected.
Actually, in a pure real-time environment, arrivals are known beforehand and are independent of completion times. However, real-time schedulers may be used to define bandwidth servers that insulate processes issuing requests with unknown arrival times. In this respect, in our implementation of SCAN-EDF, each process is associated with a relative deadline -- equal e.g., to the process' period -- which is is assigned to each request issued by the process. The (absolute) deadline of each request is then computed as the sum of the relative deadline and the maximum between the request arrival time and the deadline of the previous request of the same application. The resulting algorithm can be seen as a simple EDF-based bandwidth server: in a full-loaded system, each process should be guaranteed a bandwidth equal to the size of its requests divided by their relative deadline.
Unfortunately, this guarantee is violated for processes issuing synchronous requests. Deadlines may be missed, mainly because of the non-preemptability of request service, hence the arrival of synchronous requests may be delayed. As confirmed by the experimental results, the expected guarantees are violated because the absolute deadlines of the delayed requests are computed as a function of these deceptively delayed arrival times.
Summary of the results
In this section we report the results of our experiments with BFQ, SCAN-EDF, YFQ, CFQ, C-LOOK and AS in the Linux 2.6.21 kernel.
We used a PC equipped with a 1 GHz AMD Athlon processor, 768 MB RAM, and a (old) 30 GB IBM-DTLA-307030 ATA IDE hard drive (roughly 36 MB/sec peak bandwidth in the outer zones, ~35% lower throughput in the inner zones), accessed in UDMA mode, NCQ not available (see the draft for a discussion about the loss of guarantees caused by NCQ/TCQ). This low performance disk device helped us guarantee that it was the only bottleneck.
Then we ran several experiments aimed at measuring the aggregate throughput and long-term bandwidth distribution with parallel sequential reads, (small) file completion time/(large file) bandwidth distribution/aggregate throughput for a (seeky) Web server-like workload, request completion time and aggregate throughput for a DBMS-like random workload, and single-request completion time for a video streaming application guaranteed by the 6 schedulers. Each experiment was repeated 20 times. In what follows any mean value v is reported in the form v +/- s, where s is the semi-width of the 95% confidence interval for v.
Our implementation of SCAN-EDF exports a system-wide deadline granularity parameter. By increasing/decreasing the value of this parameter one can increase/decrease the likelihood that more requests with close deadlines are served in SCAN order.
We do not report here the detailed description of the experiments (see the draft), but only the main results.
Aggregate throughput
For any scheduler, the lowest aggregate throughputs were achieved in case of 2, 128 MB long, files, lying on two slices at the maximum distance from each other on the disk. For this scenario, the following table reports both the maximum value of the mean aggregate throughput achieved by the six schedulers and the value of the configuration parameter for which this maximum was achieved:
Whereas the highest throughput is achieved by AS, the bad performance of C-LOOK is due to the fact that it frequently switches from one file to the other, for it does not wait for the arrival of the next synchronous request of the just served application.
The high throughput achieved by BFQ results from the high number of (sequential) sectors of a file that can be read before switching to the other file. Considering the disk peak transfer rate, it is easy to see that a lower and a higher number of sequential reads are allowed, respectively, by CFQ in a 100 ms slice, and by SCAN-EDF with a granularity of 640 ms. Notably, Tw does not influence much the aggregate throughput with SCAN-EDF. In fact, the system performs read-ahead, hence it tends to asynchronously issue the next request before the completion of the current one.
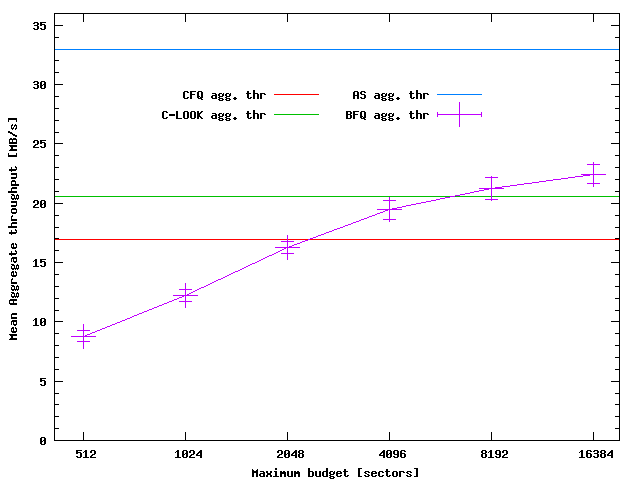
To evaluate the possible trade offs between guarantee granularity and aggregate throughput with BFQ, it is necessary to know how the throughput varies as a function of the maximum budget in the worst-case scenario. This piece of information is shown in the following figure in case of simultaneous sequential read of 2, 128 MB long, files. The aggregate throughput of CFQ, AS and C-LOOK are reported as a reference too. As can be seen, for a maximum budget equal to 4096 sectors BFQ guarantees a higher throughput than CFQ.
Bandwidth distribution
We first considered the case where all the processes are allocated the same fraction of the disk bandwidth. For each scheduler, the highest deviation from the ideal distribution occurred for 128 MB long files. Moreover, the results for 3 and 4 files "stay between" the ones achieved for 2 and 5 files. Hence, for brevity, we report here only the results for 2 and 5, 128 MB long, files.
For BFQ we only report the results for a maximum budget equal to 4096 sectors. Similarly, for SCAN-EDF, we consider only a deadline granularity of 80 ms because for this value SCAN-EDF achieves an aggregate throughput close to BFQ. In our experiments the batch size had no influence on the guarantees provided by YFQ. We report the results for a batch size of 4 requests. Finally, we consider only Tw=4 ms for SCAN-EDF and YFQ.
BFQ and YFQ exhibit the most accurate bandwidth distribution. Unfortunately, as previously seen, YFQ has a low throughput. SCAN-EDF is less accurate for 2 files, but it provides a higher throughput than YFQ. Finally, consistently with the previous arguments, CFQ fails to fairly distribute the throughput because of the varying sector transfer speed.
Moreover the high width of the confidence interval for AS is a consequence of the fact that sometimes the waiting timer may expire before the next synchronous request arrives. In that case also AS switches to the service of another application.
However, the accurate throughput distribution of YFQ and SCAN-EDF is mostly related to the symmetry of the bandwidth allocation. To measure the accuracy of the schedulers in distributing the disk bandwidth in case of asymmetric allocations, under BFQ and YFQ we assigned different weights to the (file read) processes. Of course, the length of each file was proportional to the weight of the application that had to read it. We ran two sets of experiments, using, respectively, the weights 1 and 2, and the weights 1, 2 and 10.
To try to allocate the same bandwidth as with BFQ and YFQ, under SCAN-EDF we assigned to each request of a process a relative deadline inversely proportional to the weight assigned to the process under the other two schedulers. Finally, this type of experiments was not run for CFQ, C-LOOK and AS because of the incompatibility between the concepts of weight and priority (CFQ, although, in the code of the current version it is possible to see the correspondence between priority and slice duration), or the lack of any per-application differentiated policy (C-LOOK and AS).
Finally, since, as in the previous experiments, the results for 3 and 4 files "stay between" the ones achieved for 2 and 5 files, for brevity in the following tables we report the results with BFQ only for the 2 and 5 files scenarios.
BFQ (Maximum budget = 4096 sectors)
With regards to SCAN-EDF and YFQ, both failed to guarantee the desired bandwidth distribution in all the experiments. For example, in case of 2 applications with weights 10 and 1, the throughputs were {26.58 +/- 0.50, 6.92 +/- 0.20} MB/s for SCAN-EDF, and {22.70 +/- 0.12, 5.41 +/- 0.12} MB/s for YFQ (the deviation from the expected throughputs is even attenuated by the fact that the process with a higher weight has to read a longer file, and hence it gets exclusive access to the disk after the other one finished).
Latency/Bandwidth/Aggregate throughput (Web server)
We generated the following Web server-like traffic: 100 processes (all with the same weight/priority) continuously read files one after the other. Every 10 files, each process appended a random amount of bytes, from 1 to 16 kB, to a common log file. Each of the files to read might have been, with probability 0.9, a small 16kB (html) file at a random position in the first half of the disk, or, with probability 0.1, a large file with random size in [1, 30] MB at a random position in the second half of the disk. Such a scenario allows the performance of the schedulers to be measured in presence of a mix of both sequential (large files) and a seeky traffic (small files). Especially, for each run, lasting for about one hour, we measured the completion time of each small file (latency), the (average) bandwidth at which large files were read and the average aggregate throughput (measured every second). In this respect, small and large file reads were performed in separated parts of the disk to generate an asymmetric workload, which is more prone to higher latencies and/or lower bandwidths. The table below shows the results obtained with all the disk slices mounted with NOATIME (see the compressed file for the results with ATIME).
small files [sec] |
large files [MB/s] |
||
As can be seen -- excluding for a moment SCAN-EDF and YFQ -- BFQ, CFQ and AS stand, respectively at the beginning, (about) the middle and the end of the low latency versus high aggregate throughput scale. In contrast YFQ has very low latencies and throughput because, as the probability of a small file read is 9 times higher than the one of a large file read, each batch is likely to contain a high percentage of requests pertaining to small files. In general, the low aggregate throughput achieved by SCAN-EDF and YFQ may be imputed to the fact that, differently from all the other schedulers, they do not take any special countermeasure to keep the throughput high against seeky workloads. With any scheduler, the high width of the confidence interval for the mean bandwidth of the large files is a consequence of the almost completely random nature of the workload.
DBMS
This set of experiments was aimed at estimating the request completion time and the aggregate throughput achieved by the schedulers against a DBMS-like workload: 100 processes (all with the same weight/priority) concurrently issue direct (non cacheable) 4KB read requests at random positions in a common 5GB file. We have used this setup to evaluate also the performance of the schedulers with asynchronous requests, and, to this purposes, we have run 10 variants of the experiment, with each variant characterized by a different number of per-process outstanding requests, ranging from 1 (synchronous requests) to 10. According to our results, for each scheduler both the request completion time and the aggregate throughput monotonically grew with the number of outstanding requests. Hence, for brevity we report in the following table the mean request completion time and aggregate throughput only for 1 and 10 outstanding requests.
center>outstanding requests |
time [sec] |
throughput [MB/s] |
|
With random requests, AS does not perform disk idling at all, hence it achieves the same results as pure C-LOOK. Especially, thanks to their global position-based request ordering, C-LOOK and AS achieve the lowest request completion time and hence the highest disk throughput. Being its service scheme closer to C-LOOK/AS than the one of BFQ, SCAN-EDF and CFQ, YFQ outperforms the latter in case of synchronous requests. It has instead the same performance as SCAN-EDF with 10 outstanding requests. Finally, because of their slice-by-slice/budget-by-budget service scheme both CFQ and BFQ exhibit a ~1.4 times higher request completion time/lower throughput than C-LOOK/AS. It is however worth noting that only ~2% of the disk rate is achieved by the latter, which is typically unbearable in a realistic DBMS. This result complies with the fact that, to achieve feasible response times, in applications issuing random requests caches are usually tuned so as to rarely access the disk.
Short-term time guarantees (video streaming)
We set up a VLC video streaming server, provided with 30 movies to stream to remote clients. Each movie was stored in a distinct disk slice. To evaluate the performance of the schedulers, a packet sent by the streaming thread was considered lost if delayed by more than 1 second with respect to its due transmission time (i.e., we assumed a 1 second playback buffer on the client side). Every 15 seconds the streaming of a new movie was started. Each experiment ended when the packet loss rate reached the 1% threshold. To mimic the mixed workload of a general purpose storage system and to make sure that the disk was the only bottleneck, during each experiment we also ran 5 ON/OFF file readers (details on the draft).
The following table shows the mean number of movies and the mean aggregate throughput achieved by the schedulers during the last five seconds before the end of each experiment.
As can be seen, with the maximum budget equal to 4096 sectors BFQ guarantees a stable and higher number of simultaneous streams than the other three schedulers. The poor performance of CFQ is most certainly due to its O(N) jitter.
Finally, it is worth noting that we observed that the 5 file readers tended to issue longer requests than the streaming threads. Hence the latter are further penalized under SCAN-EDF because all the requests have the same relative deadline.